环境配置
import 时找不到模块,修改python sys.path
import sys
sys.path.append(‘/home/daos/site_scons’)基础语法
编码
默认情况下,Python 3 源码文件以 UTF-8 编码,所有字符串都是 unicode 字符串。 当然你也可以为源码文件指定不同的编码:
1
# -*- coding: cp-1252 -*-
标识符
第一个字符必须是字母表中字母或下划线 _ 。
标识符的其他的部分由字母、数字和下划线组成。
标识符对大小写敏感。
在 Python 3 中,可以用中文作为变量名,非 ASCII 标识符也是允许的了。
保留字(关键字)
保留字即关键字,我们不能把它们用作任何标识符名称。Python 的标准库提供了一个 keyword 模块,可以输出当前版本的所有关键字:
1
2
3
4
5import keyword
keyword.kwlist
['False', 'None', 'True', '__peg_parser__', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']注释
1
2
3
4
5
6
7
8
9
10
11
12
13```
# 单行注释 #
print ("Hello, Python!") # 第二个注释、
# 多行注释 ''''注释内容''' 和"""注释内容"""
'''
第三注释
第四注释
'''
"""
第五注释
第六注释
"""行与缩进
python最具特色的就是使用缩进来表示代码块,不需要使用大括号 {} 。
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15```
if True:
print ("Answer")
print ("True")
else:
print ("Answer")
print ("False") # 缩进不一致,会导致运行错误
root@192 python]# python test.py
File "/home/tests/python/test.py", line 14
print ("False")
^
IndentationError: unindent does not match any outer indentation level
多行语句
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠 ** 来实现多行语句,例如:
1
2
3
4
5```
total = item_one + \
item_two + \
item_three在 [], {}, 或 () 中的多行语句,不需要使用反斜杠 ****,例如:
1
2total = ['item_one', 'item_two', 'item_three',
'item_four', 'item_five']数字类型
- int (整数), 如 1, 只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。
bool (布尔), 如 True。
- float (浮点数), 如 1.23、3E-2
- complex (复数), 如 1 + 2j、 1.1 + 2.2j
字符串
- Python 中单引号 ‘ 和双引号 “ 使用完全相同。
使用三引号(‘’’ 或 “””)可以指定一个多行字符串。
- 转义符 ****。
- 反斜杠可以用来转义,使用 r 可以让反斜杠不发生转义。 如 r”this is a line with \n” 则 \n 会显示,并不是换行。
- 按字面意义级联字符串,如 “this “ “is “ “string” 会被自动转换为 this is string。
- 字符串可以用 + 运算符连接在一起,用 ***** 运算符重复。
- Python 中的字符串有两种索引方式,从左往右以 0 开始,从右往左以 -1 开始。
- Python 中的字符串不能改变。
- Python 没有单独的字符类型,一个字符就是长度为 1 的字符串。
- 字符串的截取的语法格式如下:变量[头下标:尾下标:步长]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34word = '字符串'
sentence = "这是一个句子。"
paragraph = """这是一个段落,
可以由多行组成"""
#!/usr/bin/python3
str='123456789'
print(str) # 输出字符串
print(str[0:-1]) # 输出第一个到倒数第二个的所有字符
print(str[0]) # 输出字符串第一个字符
print(str[2:5]) # 输出从第三个开始到第五个的字符
print(str[2:]) # 输出从第三个开始后的所有字符
print(str[1:5:2]) # 输出从第二个开始到第五个且每隔一个的字符(步长为2)
print(str * 2) # 输出字符串两次
print(str + '你好') # 连接字符串
print('------------------------------')
print('hello\nrunoob') # 使用反斜杠(\)+n转义特殊字符
print(r'hello\nrunoob') # 在字符串前面添加一个 r,表示原始字符串,不会发生转义
123456789
12345678
1
345
3456789
24
123456789123456789
123456789你好
------------------------------
hello
runoob
hello\nrunoob空行
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
空行与代码缩进不同,空行并不是 Python 语法的一部分。书写时不插入空行,Python 解释器运行也不会出错。但是空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
记住:空行也是程序代码的一部分。
等待用户输入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
input("\n\n按下 enter 键后退出。")
[root@192 python]# python test.py
True
press enter to exit
```
- 同一行显示多条语句
在同一行中使用多条语句,语句之间使用分号 **;** 分割
```python
import sys; x = 'runoob'; sys.stdout.write(x + '\n')多个语句构成代码组
缩进相同的一组语句构成一个代码块,我们称之代码组。
像if、while、def和class这样的复合语句,首行以关键字开始,以冒号( : )结束,该行之后的一行或多行代码构成代码组。
我们将首行及后面的代码组称为一个子句(clause)。
1
2
3
4
5
6
7
if expression :
suite
elif expression :
suite
else :
suiteprint
print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 **end=””**:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#!/usr/bin/python3
x="a"
y="b"
# 换行输出
print( x )
print( y )
print('---------')
# 不换行输出
print( x, end=" " )
print( y, end=" " )
print()
a
b
---------
a b
import 与 from … import
在 python 用 import 或者 from…import 来导入相应的模块。
将整个模块(somemodule)导入,格式为: import somemodule
从某个模块中导入某个函数,格式为: from somemodule import somefunction
从某个模块中导入多个函数,格式为: from somemodule import firstfunc, secondfunc, thirdfunc
将某个模块中的全部函数导入,格式为: from somemodule import *
1
2
3
4
5
6
7
8
9
10
11
12
#导入sys 模块
import sys
print('================Python import mode==========================')
print ('命令行参数为:')
for i in sys.argv:
print (i)
print ('\n python 路径为',sys.path)
#导入sys模块的argv 和path成员
from sys import argv,path # 导入特定的成员
print('================python from import===================================')
print('path:',path) # 因为已经导入path成员,所以此处引用时不需要加sys.path命令行参数
稍后补充
基本数据类型
变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
变量就是变量,它没有类型,我们所说的”类型”是变量所指的内存中对象的类型。
1
2
3
4
5
6
7
8#!/usr/bin/python3
counter = 100 # 整型变量
miles = 1000.0 # 浮点型变量
name = "runoob" # 字符串
print (counter)
print (miles)
print (name)多变量赋值
1
2a = b = c = 1
a, b, c = 1, 2, "hello"标准数据类型
python3 中有6中标准数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
Number
Python3 支持 int、float、bool、complex(复数)。
内置的 type() 函数可以用来查询变量所指的对象类型。
1
2
3a, b, c, d = 20, 5.5, True, 4+3j
print(type(a), type(b), type(c), type(d))
<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>还可以用 isinstance 来判断:
1
2
3
4a = 111
isinstance(a, int)
True
>>>isinstance 和 type 的区别在于:
- type()不会认为子类是一种父类类型。
- isinstance()会认为子类是一种父类类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30class A:
pass
class B(A):
pass
isinstance(A(), A)
True
type(A()) == A
True
isinstance(B(), A)
True
type(B()) == A
False
注意:Python3 中,bool 是 int 的子类,True 和 False 可以和数字相加, True==1、False==0 会返回 True,但可以通过 is 来判断类型。
issubclass(bool, int)
True
True==1
True
False==0
True
True+1
2
False+1
1
1 is True
False
0 is False
False使用del语句删除单个或多个对象。例如:
1
2del var
del var_a, var_b数值运算
1
2
3
4
5
6
7
8
9
10
11
12
13
145 + 4 # 加法
9
4.3 - 2 # 减法
2.3
3 * 7 # 乘法
21
2 / 4 # 除法,得到一个浮点数
0.5
2 // 4 # 除法,得到一个整数
0
17 % 3 # 取余
2
2 ** 5 # 乘方
32String
使用单引号’’或双引号””将字符串括起来,并使用\转义特殊字符
反斜杠()可以作为续行符,表示下一行是上一行的延续。也可以使用 “””…””” 或者 ‘’’…’’’ 跨越多行
字符串的截取格式:变量[头下标:尾下标]
从前索引:索引值从0开始
从后索引:索引值从-1开始
+:字符串连接符
*数字:复制当前字符串,数字是复制的次数
实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# -*- coding: utf-8 -*-
#!/usr/bin/python3.6
str = 'string'
print(str)
print(str[0:-1]) #打印第一个到倒数第二个字符
print(str[0])
print(str[2:5]) #第三个到第五个,注意与上面的[0:-1]有区别
print(str*2)
print(str+'TEST')
print('stri\ng')
print(r'stri\ng')
[root@192 python]# python data_type.py
string
strin
s
rin
stringstring
stringTEST
stri
g
stri\ngList
使用最频繁的数据类型
列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
- 1、List写在方括号之间,元素用逗号隔开。
- 2、和字符串一样,list可以被索引和切片。
- 3、List可以使用+操作符进行拼接。
- 4、List中的元素是可以改变的。
1
2
3变量[头下标:尾下标] 也可以 变量[头下标:尾下标:步长]
索引值以 0 为开始值,-1 为从末尾的开始位置。
实例1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29list = ['a', 1, 2.3, 4.56]
tinylist = ['123', 'tinylist']
print(list)
print(list[0])
print(list[1:3])
print(list[2:])
print(tinylist*2)
print(list+tinylist)
list[0] = 9
print(list)
list[1:3] = [8, 7]
print(list)
list[3:]=[]
print(list)
list.append(6)
print(list)
print(list[0:3:2])
[root@192 python]# python data_type.py
['a', 1, 2.3, 4.56]
a
[1, 2.3]
[2.3, 4.56]
['123', 'tinylist', '123', 'tinylist']
['a', 1, 2.3, 4.56, '123', 'tinylist']
[9, 1, 2.3, 4.56]
[9, 8, 7, 4.56]
[9, 8, 7]
[9, 8, 7, 6]
[9, 7]List 内置了很多方法,如append()、pop()等
实例2 字符翻转
1
2
3
4
5
6
7
8
9
10
11
12def reverserWords(input):
inputWords = input.split(' ')
inputWords = inputWords[-1::-1]
output = ' '.join(inputWords)
return output
if __name__ == "__main__":
input = 'I like you'
rw = reverserWords(input)
print(rw)
元组
1、与字符串一样,元组的元素不能修改。
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
2、元组也可以被索引和切片,方法一样。
3、注意构造包含 0 或 1 个元素的元组的特殊语法规则。
1
2tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号4、元组也可以使用+操作符进行拼接。
5、
Set 集合
集合(set)是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。
基本功能是进行成员关系测试和删除重复元素。
创建格式:注意创建一个空集,必须用set() 而不能用{}(因为{}是用来创建一个空字典)
1
2
3parame = {value1, value2, ...}
或者
set(value)实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26#set
sites = {'google', 'baidu', 'ali'}
print(sites)
if 'ali' in sites:
print('ali in sites')
else:
print('ali not in sites ')
#set 集合运算
a=set('abracadabra')
b=set('alacazam')
print(a)
print(a - b) #差集
print(a | b) #并集
print(a & b) #交集
print(a ^ b) #a和b中不同时存在的元素
输出:
set(['baidu', 'google', 'ali'])
ali in sites
set(['a', 'r', 'b', 'c', 'd'])
set(['r', 'b', 'd'])
set(['a', 'c', 'b', 'd', 'm', 'l', 'r', 'z'])
set(['a', 'c'])
set(['b', 'd', 'm', 'l', 'r', 'z'])Dictionary
- 1、非常有用的内置数据类型
- 2、字典是一种映射类型,它的元素是键值对。一个无序的 键(key) : 值(value) 的集合
- 3、字典的关键字必须为不可变类型,且不能重复。
- 4、创建空字典使用 { }。
- 5、在同一个字典中,键(key)必须是唯一的
- 6、构造函数 dict() 可以直接从键值对序列中构建字典
- 7、字典类型也有一些内置的函数,例如 clear()、keys()、values() 等。
实例1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16dict = {}
dict['one'] = 'you'
dict[2] = 'me'
tinydict = {'one':'you', 'two':'and', 'three':'me'}
print(dict['one'])
print(dict[2])
print(tinydict.keys())
print(tinydict.values())
输出:
you
me
['three', 'two', 'one']
['me', 'and', 'you']实例2
1
2
3
4
5
6dict([('Runoob', 1), ('Google', 2), ('Taobao', 3)])
{'Runoob': 1, 'Google': 2, 'Taobao': 3}
{x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
dict(Runoob=1, Google=2, Taobao=3)
{'Runoob': 1, 'Google': 2, 'Taobao': 3}
数据类型转换
Python 数据类型转换可以分为两种:
隐式类型转换 - 自动完成
较低数据类型(整数)就会转换为较高数据类型(浮点数)以避免数据丢失。
显式类型转换 - 需要使用类型函数来转换
在显式类型转换中,用户将对象的数据类型转换为所需的数据类型。 我们使用 int()、float()、str() 等预定义函数来执行显式类型转换。
整型和字符串类型进行运算,就可以用强制类型转换来完成
常用的几个内置函数:
函数 描述 [int(x ,base]) 将x转换为一个整数 float(x) 将x转换到一个浮点数 [complex(real ,imag]) 创建一个复数 str(x) 将对象 x 转换为字符串 repr(x) 将对象 x 转换为表达式字符串 eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象 tuple(s) 将序列 s 转换为一个元组 list(s) 将序列 s 转换为一个列表 set(s) 转换为可变集合 dict(d) 创建一个字典。d 必须是一个 (key, value)元组序列。 frozenset(s) 转换为不可变集合 chr(x) 将一个整数转换为一个字符 ord(x) 将一个字符转换为它的整数值 hex(x) 将一个整数转换为一个十六进制字符串 oct(x)
推导式
Python 推导式是一种独特的数据处理方式,可以从一个数据序列构建另一个新的数据序列的结构体。
Python 支持各种数据结构的推导式:
- 列表(list)推导式
- 字典(dict)推导式
- 集合(set)推导式
- 元组(tuple)推导式
列表推导式
推导式格式:
1
2
3
4
5
6
7
8
9[表达式 for 变量 in 列表]
[out_exp_res for out_exp in input_list]
或者
[表达式 for 变量 in 列表 if 条件]
[out_exp_res for out_exp in input_list if condition]
说明
out_exp_res:列表生成元素表达式,可以是有返回值的函数。
for out_exp in input_list:迭代 input_list 将 out_exp 传入到 out_exp_res 表达式中。
if condition:条件语句,可以过滤列表中不符合条件的值。实例1:过滤掉长度小于或等于3的字符串列表,并将剩下的转换成大写字母:
1
2
3
4names = ['Bob','Tom','alice','Jerry','Wendy','Smith']
new_names = [name.upper()for name in names if len(name)>3]
print(new_names)
['ALICE', 'JERRY', 'WENDY', 'SMITH']实例2:计算 30 以内可以被 3 整除的整数
1
2multiples = [i for i in range(30) if i % 3 == 0]
print(multiples)字典推导式
格式:
1
2
3{ key_expr: value_expr for value in collection }
或
{ key_expr: value_expr for value in collection if condition }实例1:使用字符串及其长度创建字典
1
2
3
4
5list =['beijing', 'shanghai', 'guangzhou','shenzhen']
dic = {key:len(key) for key in list}
print(dic)
输出:
{'beijing': 7, 'shanghai': 8, 'guangzhou': 9, 'shenzhen': 8}实例2:将三个整数及其平方值作为键值对创建字典
1
2
3
4dic = {i : i**2 for i in (1,2,3)}
print(dic)
输出:
{1: 1, 2: 4, 3: 9}集合推导式
格式:
1
2
3{ expression for item in Sequence }
或
{ expression for item in Sequence if conditional }实例1:计算1,2,3平方
1
set = {x**2 for x in (1,2,3)}
实例2:判断不是abc的字母并输出
1
a = {x for x in 'abclsm' if x not in 'abc'}
元组推导式
元组推导式可以利用 range 区间、元组、列表、字典和集合等数据类型,快速生成一个满足指定需求的元组。
元组推导式和列表推导式的用法也完全相同,只是元组推导式是用 () 圆括号将各部分括起来,而列表推导式用的是中括号 **[]**,另外元组推导式返回的结果是一个生成器对象。
格式:
1
2
3(expression for item in Sequence )
或
(expression for item in Sequence if conditional )实例1:生成一个包含数字 1~9 的元组:
1
2
3
4
5
6a = (x for x in range(1,10))
a
<generator object <genexpr> at 0x7faf6ee20a50> # 返回的是生成器对象
tuple(a) # 使用 tuple() 函数,可以直接将生成器对象转换成元组
(1, 2, 3, 4, 5, 6, 7, 8, 9)解释器
python 的二进制文件
交互式编程
脚本式编程
注释
确保对模块, 函数, 方法和行内注释使用正确的风格。
Python 中的注释有单行注释和多行注释。
Python 中单行注释以 # 开头,例如:
# 这是一个注释 print(“Hello, World!”)
多行注释用三个单引号 ‘’’ 或者三个双引号 “”” 将注释括起来,例如:
单引号(’’’)
#!/usr/bin/python3 ‘’’ 这是多行注释,用三个单引号 这是多行注释,用三个单引号 这是多行注释,用三个单引号 ‘’’ print(“Hello, World!”)
双引号(”””)
#!/usr/bin/python3 “”” 这是多行注释,用三个双引号 这是多行注释,用三个双引号 这是多行注释,用三个双引号 “”” print(“Hello, World!”)
运算符
Python 语言支持以下类型的运算符:
以下表格列出了从最高到最低优先级的所有运算符:
运算符 描述 ** 指数 (最高优先级) ~ + - 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) * / % // 乘,除,求余数和取整除 + - 加法减法 >> << 右移,左移运算符 & 位 ‘AND’ ^ | 位运算符 <= < > >= 比较运算符 == != 等于运算符 = %= /= //= -= += *= **= 赋值运算符 is is not 身份运算符 in not in 成员运算符 not and or 逻辑运算符 数字
字符串
注:只记录新的东西,使用与 C 中 sprintf 函数一样的语法,不同的是后面的变量前面有个%
字符串格式化:
如 print (“我叫 %s 今年 %d 岁!” % (‘小明’, 10))
新的格式化方式 str.format() 通过 {} 和 **.**来代替以前的 % 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
"{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
"{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
也可设置参数
#!/usr/bin/python
# -*- coding: UTF-8 -*-
print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com"))
# 通过字典设置参数
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{name}, 地址 {url}".format(**site))
# 通过列表索引设置参数
my_list = ['菜鸟教程', 'www.runoob.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的
# 向str.format() 传入对象 不明白这里
class AssignValue(object):
def __init__(self, value):
self.value = value
my_value = AssignValue(6)
print('value 为: {0.value}'.format(my_value)) # "0" 是可选的- 数字格式化
1
2print("{:.2f}".format(3.1415926))
3.14
列表
一些列表操作:
更新列表
1
2list = []
list.append('test')删除列表元素
1
2
3del list[0]
print list
[]操作符
1
2
3
4
5
6
7
8
9
10
11
12
13
14#len(list)
list.append('test')
len(list)
1
# + 组合列表 -> 新列表
[1] + list
[1, 'test']
# * 重复列表 -> 新列表
list * 2
['test', 'test']
# in 检查成员
'test' in list
True
# for x in [1,2,3]: print x函数和方法
序号 函数 1 cmp(list1, list2) 比较两个列表的元素 2 len(list) 列表元素个数 3 max(list) 返回列表元素最大值 4 min(list) 返回列表元素最小值 5 list(seq) 将元组转换为列表 序号 方法 1 list.append(obj) 在列表末尾添加新的对象 2 list.count(obj) 统计某个元素在列表中出现的次数 3 list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) 4 list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 5 list.insert(index, obj) 将对象插入列表 6 [list.pop(index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 7 list.remove(obj) 移除列表中某个值的第一个匹配项 8 list.reverse() 反向列表中元素 9 list.sort(cmp=None, key=None, reverse=False) 对原列表进行排序
元组
- 创建
tup1 = (‘physics’, ‘chemistry’, 1997, 2000) tup2 = (1, 2, 3, 4, 5 ) tup3 = “a”, “b”, “c”, “d”
创建空元组
1
tup1 = ()
元组中只包含一个元素时,需要在元素后面添加逗号
1
tup1 = (50,)
元组与字符串类似,下标索引从0开始,可以进行截取,组合等。
访问
索引或切片
修改
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合
tup1 = (12, 34.56) tup2 = (‘abc’, ‘xyz’) # 以下修改元组元素操作是非法的。 # tup1[0] = 100 # 创建一个新的元组 tup3 = tup1 + tup2 print tup3 输出(12, 34.56, ‘abc’, ‘xyz’)
删除
del tup
运算符
Python 表达式 结果 描述 len((1, 2, 3)) 3 计算元素个数 (1, 2, 3) + (4, 5, 6) (1, 2, 3, 4, 5, 6) 连接 (‘Hi!’,) * 4 (‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’) 复制 3 in (1, 2, 3) True 元素是否存在 for x in (1, 2, 3): print x, 1 2 3 迭代 任意无符号的对象,以逗号隔开,默认为元组
1
2
3
4
5
6print 'abc', -4.24e93, 18+6.6j, 'xyz'
x, y = 1, 2
print "Value of x , y : ", x,y
abc -4.24e+93 (18+6.6j) xyz
Value of x , y : 1 2内置 函数
序号 方法及描述 1 cmp(tuple1, tuple2) 比较两个元组元素。 2 len(tuple) 计算元组元素个数。 3 max(tuple) 返回元组中元素最大值。 4 min(tuple) 返回元组中元素最小值。 5 tuple(seq) 将列表转换为元组。
字典
创建字典
1
2
3
4
5
6
7
8
9
10
11
12
13
14tinydict1 = { 'abc': 456 }
tinydict2 = { 'abc': 123, 98.6: 37 }
# 使用大括号 {} 来创建空字典
emptyDict = {}
# 打印字典
print(emptyDict)
# 查看字典的数量
print("Length:", len(emptyDict))
# 查看类型
print(type(emptyDict))
# 使用dict() 创建
emptyDict = dict()访问
1
2
3tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print ("tinydict['Name']: ", tinydict['Name'])
print ("tinydict['Age']: ", tinydict['Age'])修改
1
2
3
4
5tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
tinydict['Age'] = 8 # 更新 Age
tinydict['School'] = "菜鸟教程" # 添加信息
print ("tinydict['Age']: ", tinydict['Age'])
print ("tinydict['School']: ", tinydict['School'])删除元素
1
2
3
4
5del tinydict['Name'] # 删除键 'Name'
tinydict.clear() # 清空字典
del tinydict # 删除字典
print ("tinydict['Age']: ", tinydict['Age'])
print ("tinydict['School']: ", tinydict['School'])键特性
两个重要的点需要记住:
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住
2)键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行
内置函数和方法
号 函数及描述 实例 1 len(dict) 计算字典元素个数,即键的总数。 >>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} >>> len(tinydict) 32 str(dict) 输出字典,可以打印的字符串表示。 >>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} >>> str(tinydict) "{'Name': 'Runoob', 'Class': 'First', 'Age': 7}"3 type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 >>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} >>> type(tinydict) <class 'dict'>序号 函数及描述 1 dict.clear() 删除字典内所有元素 2 dict.copy() 返回一个字典的浅复制 3 dict.fromkeys() 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 4 dict.get(key, default=None) 返回指定键的值,如果键不在字典中返回 default 设置的默认值 5 key in dict 如果键在字典dict里返回true,否则返回false 6 dict.items() 以列表返回一个视图对象 7 dict.keys() 返回一个视图对象 8 dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default 9 dict.update(dict2) 把字典dict2的键/值对更新到dict里 10 dict.values() 返回一个视图对象 11 [pop(key,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 12 popitem() 返回并删除字典中的最后一对键和值。
集合
一个无序的不重复元素序列。
创建
1
2
3
4
5
6
7
8
9
10parame = {value01,value02,...}
或者
set(value)
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # 这里演示的是去重功能
{'orange', 'banana', 'pear', 'apple'}
'orange' in basket # 快速判断元素是否在集合内
True
'crabgrass' in basket
False添加元素
1
2
3
4
5
6
7
8
9s.add( x ) #将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作
s.update( x ) #参数可以是列表,元组,字典等
thisset = set(("Google", "Runoob", "Taobao"))
thisset.update({1,3})
print(thisset)
{1, 3, 'Google', 'Taobao', 'Runoob'}
thisset.update([1,4],[5,6])
print(thisset)
{1, 3, 4, 5, 6, 'Google', 'Taobao', 'Runoob'}删除元素
1
2
3s.remove( x ) #将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误
s.discard( x ) #如果元素不存在,不会发生错误
s.pop() #随机删除集合中的一个元素,set 集合的 pop 方法会对集合进行无序的排列,然后将这个无序排列集合的左面第一个元素进行删除计算元素个数
1
len(s)
清空集合
1
s.clear()
判断元素是否存在
1
x in s
内置方法
方法 描述 add() 为集合添加元素 clear() 移除集合中的所有元素 copy() 拷贝一个集合 difference() 返回多个集合的差集 difference_update() 移除集合中的元素,该元素在指定的集合也存在。 discard() 删除集合中指定的元素 intersection() 返回集合的交集 intersection_update() 返回集合的交集。 isdisjoint() 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 issubset() 判断指定集合是否为该方法参数集合的子集。 issuperset() 判断该方法的参数集合是否为指定集合的子集 pop() 随机移除元素 remove() 移除指定元素 symmetric_difference() 返回两个集合中不重复的元素集合。 symmetric_difference_update() 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 union() 返回两个集合的并集 update() 给集合添加元素
条件控制
- if
- 1、每个条件后面要使用冒号 **:**,表示接下来是满足条件后要执行的语句块。
- 2、使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块。
- 3、在Python中没有switch – case语句。
- if-elif-else : python 中无else if 而使用elif
- if 嵌套
- if
循环语句
Python 中的循环语句有 for 和 while,同样需要注意冒号和缩进。另外,在 Python 中没有 do..while 循环
while
1
2while 判断条件(condition):
执行语句(statements)……while else
1
2
3
4while <expr>:
<statement(s)>
else:
<additional_statement(s)>简单语句组
类似if语句的语法,如果你的while循环体中只有一条语句,你可以将该语句与while写在同一行中
1
flag = 1 while (flag): print ('欢迎访问菜鸟教程!') print ("Good bye!")
for
for 循环可以遍历任何可迭代对象,如一个列表或者一个字符串
1
2
3
4for <variable> in <sequence>:
<statements>
else:
<statements>range()
遍历数字序列,可以使用内置range()函数。它会生成数列
结合range()和len()函数以遍历一个序列的索引
使用range()函数来创建一个列表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25>>>for i in range(5):
print(i)
...
0
1
2
3
4
>>>for i in range(0, 10, 3) :
print(i)
0
3
6
9
>>>a = ['Google', 'Baidu', 'Runoob', 'Taobao', 'QQ']
for i in range(len(a)):
print(i, a[i])
0 Google
1 Baidu
2 Runoob
3 Taobao
4 QQ
>>>list(range(5))
[0, 1, 2, 3, 4]pass
pass是空语句,是为了保持程序结构的完整性,不做任何事情,一般用做占位语句
迭代器与生成器
迭代器
迭代是Python最强大的功能之一,是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 **next()**。
1
2
3
4
5
6
7
8
9
10
11
12
13#字符串,列表或元组对象都可用于创建迭代器
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
print (next(it)) # 输出迭代器的下一个元素
1
print (next(it))
2
#迭代器对象可以使用常规for语句进行遍历:
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
for x in it:
print (x, end=" ")
1 2 3 4创建
把一个类作为一个迭代器使用需要在类中实现两个方法__ iter() 与__ next()
__ iter() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 next() 方法并通过 StopIteration 异常标识迭代的完成。
__ next() 方法(Python 2 里是 next())会返回下一个迭代器对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
x = self.a
self.a += 1
return x
myclass = MyNumbers()
myiter = iter(myclass)
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
1
2
3
4
5
#StopIteration 异常用于标识迭代的完成,防止出现无限循环的情况,在 __next__() 方法中我们可以设置在完成指定循环次数后触发 StopIteration 异常来结束迭代。
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
if self.a <= 20:
x = self.a
self.a += 1
return x
else:
raise StopIteration
myclass = MyNumbers()
myiter = iter(myclass)
for x in myiter:
print(x)
生成器
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import sys
def fibonacci(n): # 生成器函数 - 斐波那契
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True:
try:
print (next(f), end=" ")
except StopIteration:
sys.exit()
0 1 1 2 3 5 8 13 21 34 55
函数
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 **()**。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号 : 起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方,不带表达式的 return 相当于返回 None。
格式:
1
2def 函数名(参数列表):
函数体参数传递
在 python 中,类型属于对象,对象有不同类型的区分,变量是没有类型的
1
2
3a=[1,2,3]
a="Runoob"以上代码中,**[1,2,3]** 是 List 类型,**”Runoob”** 是 String 类型,而变量 a 是没有类型,她仅仅是一个对象的引用(一个指针),可以是指向 List 类型对象,也可以是指向 String 类型对象。
可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
- 不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变 a 的值,相当于新生成了 a。
- 可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
- 不可变类型:类似 C++ 的值传递,如整数、字符串、元组。如 fun(a),传递的只是 a 的值,没有影响 a 对象本身。如果在 fun(a) 内部修改 a 的值,则是新生成一个 a 的对象。
- 可变类型:类似 C++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后 fun 外部的 la 也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26#传不可变对象 通过 id() 函数来查看内存地址变化:
def change(a):
print(id(a)) # 指向的是同一个对象
a=10
print(id(a)) # 一个新对象
a=1
print(id(a))
change(a)
4379369136
4379369136
4379369424
#传可变对象 通过 id() 函数来查看内存地址变化:
# 可写函数说明
def changeme( mylist ):
"修改传入的列表"
mylist.append([1,2,3,4])
print ("函数内取值: ", mylist)
return
# 调用changeme函数
mylist = [10,20,30]
changeme( mylist )
print ("函数外取值: ", mylist)
函数内取值: [10, 20, 30, [1, 2, 3, 4]]
函数外取值: [10, 20, 30, [1, 2, 3, 4]]参数
必需参数
必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
关键字参数
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16#可写函数说明
def printme( str ):
"打印任何传入的字符串"
print (str)
return
#调用printme函数
printme( str = "菜鸟教程")
#不需要使用指定顺序
#可写函数说明
def printinfo( name, age ):
"打印任何传入的字符串"
print ("名字: ", name)
print ("年龄: ", age)
return
#调用printinfo函数
printinfo( age=50, name="runoob" )默认参数
调用函数时,如果没有传递参数,则会使用默认参数。以下实例中如果没有传入 age 参数,则使用默认值:
1
2
3
4
5
6
7
8
9
10#可写函数说明
def printinfo( name, age = 35 ):
"打印任何传入的字符串"
print ("名字: ", name)
print ("年龄: ", age)
return
#调用printinfo函数
printinfo( age=50, name="runoob" )
print ("------------------------")
printinfo( name="runoob" )不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述 2 种参数不同,声明时不会命名。基本语法如下:
1
2
3
4
5def functionname([formal_args,] *var_args_tuple ):
"函数_文档字符串"
function_suite
return [expression]
加了星号 * 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数。1
2
3
4
5
6
7
8
9
10
11# 可写函数说明
def printinfo( arg1, *vartuple ):
"打印任何传入的参数"
print ("输出: ")
print (arg1)
print (vartuple)
# 调用printinfo 函数
printinfo( 70, 60, 50 )
输出:
70
(60, 50)还有一种就是参数带两个星号 ******基本语法如下:
1
2
3
4
5def functionname([formal_args,] **var_args_dict ):
"函数_文档字符串"
function_suite
return [expression]
加了两个星号 ** 的参数会以字典的形式导入1
2
3
4
5
6
7
8
9
10
11
12
13# 可写函数说明
def printinfo( arg1, **vardict ):
"打印任何传入的参数"
print ("输出: ")
print (arg1)
print (vardict)
# 调用printinfo 函数
printinfo(1, a=2,b=3)
输出:
1
{'a': 2, 'b': 3}声明函数时,参数中星号 ***** 可以单独出现,例如:
1
2
3
4
5
6
7
8
9
10
11def f(a,b,*,c):
return a+b+c
def f(a,b,*,c):
return a+b+c
f(1,2,3) # 报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: f() takes 2 positional arguments but 3 were given
f(1,2,c=3) # 正常
6匿名函数
Python 使用 lambda 来创建匿名函数。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda 的主体是一个表达式,而不是一个代码块。仅仅能在 lambda 表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然 lambda 函数看起来只能写一行,却不等同于 C 或 C++ 的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
lambda 函数的语法只包含一个语句,如下:
1
lambda [arg1 [,arg2,.....argn]]:expression
1
2
3
4
5
6
7
8
9#一个参数
x = lambda a : a + 10
print(x(5))
#多个参数
# 可写函数说明
sum = lambda arg1, arg2: arg1 + arg2
# 调用sum函数
print ("相加后的值为 : ", sum( 10, 20 ))
print ("相加后的值为 : ", sum( 20, 20 ))可以将匿名函数封装在一个函数内,这样可以使用同样的代码来创建多个匿名函数。
1
2
3
4
5
6
7
8def myfunc(n):
return lambda a : a * n
mydoubler = myfunc(2)
mytripler = myfunc(3)
print(mydoubler(11))
print(mytripler(11))数据结构
模块
Python 提供了一个办法,把这些定义存放在文件中,为一些脚本或者交互式的解释器实例使用,这个文件被称为模块。
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。
- 1、import sys 引入 python 标准库中的 sys.py 模块;这是引入某一模块的方法。
- 2、sys.argv 是一个包含命令行参数的列表。
- 3、sys.path 包含了一个 Python 解释器自动查找所需模块的路径的列表。
深入模块
输入输出
输出格式美化
Python两种输出值的方式: 表达式语句和 print() 函数。
第三种方式是使用文件对象的 write() 方法,标准输出文件可以用 sys.stdout 引用。
如果你希望输出的形式更加多样,可以使用 str.format() 函数来格式化输出值。
如果你希望将输出的值转成字符串,可以使用 repr() 或 str() 函数来实现。
- str(): 函数返回一个用户易读的表达形式。
- repr(): 产生一个解释器易读的表达形式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20s = 'Hello, Runoob'
str(s)
'Hello, Runoob'
repr(s)
"'Hello, Runoob'"
str(1/7)
'0.14285714285714285'
x = 10 * 3.25
y = 200 * 200
s = 'x 的值为: ' + repr(x) + ', y 的值为:' + repr(y) + '...'
print(s)
x 的值为: 32.5, y 的值为:40000...
# repr() 函数可以转义字符串中的特殊字符
hello = 'hello, runoob\n'
hellos = repr(hello)
print(hellos)
'hello, runoob\n'
# repr() 的参数可以是 Python 的任何对象
repr((x, y, ('Google', 'Runoob')))
"(32.5, 40000, ('Google', 'Runoob'))"- str.format()
#括号及其里面的字符 (称作格式化字段) 将会被 format() 中的参数替换
>>> print(‘{}网址: “{}!”‘.format(‘菜鸟教程’, ‘www.runoob.com'))
菜鸟教程网址: “www.runoob.com!"#在括号中的数字用于指向传入对象在 format() 中的位置
>>> print(‘{0} 和 {1}’.format(‘Google’, ‘Runoob’))
Google 和 Runoob
>>> print(‘{1} 和 {0}’.format(‘Google’, ‘Runoob’))
Runoob 和 Google#如果在 format() 中使用了关键字参数, 那么它们的值会指向使用该名字的参数
>>> print(‘{name}网址: {site}’.format(name=’菜鸟教程’, site=’www.runoob.com'))
菜鸟教程网址: www.runoob.com#位置及关键字参数可以任意的结合
>>> print(‘站点列表 {0}, {1}, 和 {other}。’.format(‘Google’, ‘Runoob’, other=’Taobao’))
站点列表 Google, Runoob, 和 Taobao。#!a (使用 ascii()), !s (使用 str()) 和 !r (使用 repr()) 可以用于在格式化某个值之前对其进行转化:
1
2
3
4
5import math
print('常量 PI 的值近似为: {}。'.format(math.pi))
常量 PI 的值近似为: 3.141592653589793。
print('常量 PI 的值近似为: {!r}。'.format(math.pi))
常量 PI 的值近似为: 3.141592653589793。#可选项 : 和格式标识符可以跟着字段名。 这就允许对值进行更好的格式化。 下面的例子将 Pi 保留到小数点后三位:
1
2
3import math
print('常量 PI 的值近似为 {0:.3f}。'.format(math.pi))
常量 PI 的值近似为 3.142。#在 : 后传入一个整数, 可以保证该域至少有这么多的宽度。 用于美化表格时很有用
1
2
3
4
5
6
7table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
for name, number in table.items():
print('{0:10} ==> {1:10d}'.format(name, number))
...
Google ==> 1
Runoob ==> 2
Taobao ==> 3旧式字符串格式化
% 操作符也可以实现字符串格式化。 它将左边的参数作为类似 sprintf() 式的格式化字符串, 而将右边的代入, 然后返回格式化后的字符串.
但是因为这种旧式的格式化最终会从该语言中移除, 应该更多的使用 str.format().
1
2
3import math
print('常量 PI 的值近似为:%5.3f。' % math.pi)
常量 PI 的值近似为:3.142。读取键盘输入
使用input()内置函数从标准输入读入一行文本,默认的标准输入是键盘
1
2
3#!/usr/bin/python3
str = input("请输入:");
print ("你输入的内容是: ", str)读写文件
open() 将会返回一个 file 对象:
1
2
3open(filename, mode)
filename:包含了你要访问的文件名称的字符串值。
mode:决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。实例
1
2
3
4
5# 打开一个文件
f = open("/tmp/foo.txt", "w")
f.write( "Python 是一个非常好的语言。\n是的,的确非常好!!\n" )
# 关闭打开的文件
f.close()不同模式打开文件的完全列表:
模式 描述 r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 r+ 打开一个文件用于读写。文件指针将会放在文件的开头。 rb+ 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 w 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 w+ 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 ab 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 a+ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 ab+ 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 模式 r r+ w w+ a a+ 读 + + + + 写 + + + + + 创建 + + + + 覆盖 + + 指针在开始 + + + + 指针在结尾 + + 文件对象方法
f.read()
#调用 f.read(size), 这将读取一定数目的数据, 然后作为字符串或字节对象返回。size 是一个可选的数字类型的参数。 当 size 被忽略了或者为负, 那么该文件的所有内容都将被读取并且返回。
实例
1
2
3
4
5
6
7
8
9
10#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "r")
str = f.read()
print(str)
# 关闭打开的文件
f.close()
Python 是一个非常好的语言。
是的,的确非常好!!f.readline()
#f.readline() 会从文件中读取单独的一行。换行符为 ‘\n’。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行。
实例
1
2
3
4
5
6
7
8# 打开一个文件
f = open("/tmp/foo.txt", "r")
str = f.readline()
print(str)
# 关闭打开的文件
f.close()
Python 是一个非常好的语言。f.readlines()
#返回该文件中包含的所有行。
#如果设置可选参数 sizehint, 则读取指定长度的字节, 并且将这些字节按行分割。
实例1
1
2
3
4
5
6
7
8
9#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "r")
str = f.readlines()
print(str)
# 关闭打开的文件
f.close()
输出
['Python 是一个非常好的语言。\n', '是的,的确非常好!!\n']实例2 迭代一个文件对象然后读取每行:
1
2
3
4
5
6
7
8
9# 打开一个文件
f = open("/tmp/foo.txt", "r")
for line in f:
print(line, end='')
# 关闭打开的文件
f.close()
执行以上程序,输出结果为:
Python 是一个非常好的语言。
是的,的确非常好!!f.write()
f.write(string) 将 string 写入到文件中, 然后返回写入的字符数。
1
2
3
4
5
6
7
8
9#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "w")
num = f.write( "Python 是一个非常好的语言。\n是的,的确非常好!!\n" )
print(num)
# 关闭打开的文件
f.close()
执行以上程序,输出结果为:
29如果要写入一些不是字符串的东西, 那么将需要先进行转换:
1
2
3
4
5
6
7
8
9
10
11#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo1.txt", "w")
value = ('www.runoob.com', 14)
s = str(value)
f.write(s)
# 关闭打开的文件
f.close()
执行以上程序,打开 foo1.txt 文件:
$ cat /tmp/foo1.txt
('www.runoob.com', 14)f.tell()
f.tell() 返回文件对象当前所处的位置, 它是从文件开头开始算起的字节数。
f.seek()
如果要改变文件当前的位置, 可以使用 f.seek(offset, from_what) 函数。
from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾,例如:
- seek(x,0) : 从起始位置即文件首行首字符开始移动 x 个字符
- seek(x,1) : 表示从当前位置往后移动x个字符
- seek(-x,2):表示从文件的结尾往前移动x个字符
from_what 值为默认为0,即文件开头。下面给出一个完整的例子:
1
2
3
4
5
6
7
8
9
10
11f = open('/tmp/foo.txt', 'rb+')
f.write(b'0123456789abcdef')
16
f.seek(5) # 移动到文件的第六个字节
5
f.read(1)
b'5'
f.seek(-3, 2) # 移动到文件的倒数第三字节
13
f.read(1)
b'd'f.close()
当你处理完一个文件后, 调用 f.close() 来关闭文件并释放系统的资源,如果尝试再调用该文件,则会抛出异常。
1
2
3
4
5f.close()
f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ValueError: I/O operation on closed file当处理一个文件对象时, 使用 with 关键字是非常好的方式。在结束后, 它会帮你正确的关闭文件。 而且写起来也比 try - finally 语句块要简短:
1
2
3
4with open('/tmp/foo.txt', 'r') as f:
read_data = f.read()
f.closed
Truepickle 模块
python的pickle模块实现了基本的数据序列和反序列化。
通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储。
通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
基本接口:
1
pickle.dump(obj, file, [,protocol])
有了 pickle 这个对象, 就能对 file 以读取的形式打开:
1
x = pickle.load(file)
注解:从 file 中读取一个字符串,并将它重构为原来的python对象。
file: 类文件对象,有read()和readline()接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import pickle
# 使用pickle模块将数据对象保存到文件
data1 = {'a': [1, 2.0, 3, 4+6j],
'b': ('string', u'Unicode string'),
'c': None}
selfref_list = [1, 2, 3]
selfref_list.append(selfref_list)
output = open('data.pkl', 'wb')
# Pickle dictionary using protocol 0.
pickle.dump(data1, output)
# Pickle the list using the highest protocol available.
pickle.dump(selfref_list, output, -1)
output.close()1
2
3
4
5
6
7
8
9
10
11
12import pprint, pickle
#使用pickle模块从文件中重构python对象
pkl_file = open('data.pkl', 'rb')
data1 = pickle.load(pkl_file)
pprint.pprint(data1)
data2 = pickle.load(pkl_file)
pprint.pprint(data2)
pkl_file.close()
File
- open()方法
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
1
open(file, mode='r')
完整的语法格式为:
1
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
mode 参数有:
模式 描述 t 文本模式 (默认)。 x 写模式,新建一个文件,如果该文件已存在则会报错。 b 二进制模式。 + 打开一个文件进行更新(可读可写)。 U 通用换行模式(Python 3 不支持)。 r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 r+ 打开一个文件用于读写。文件指针将会放在文件的开头。 rb+ 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 w 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 w+ 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 ab 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 a+ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 ab+ 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 默认为文本模式,如果要以二进制模式打开,加上 b 。
file 对象
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
序号 方法及描述 1 file.close()关闭文件。关闭后文件不能再进行读写操作。 2 file.flush()刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 3 file.fileno()返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 4 file.isatty()如果文件连接到一个终端设备返回 True,否则返回 False。 5 file.next()Python 3 中的 File 对象不支持 next() 方法。返回文件下一行。 6 [file.read(size])从文件读取指定的字节数,如果未给定或为负则读取所有。 7 [file.readline(size])读取整行,包括 “\n” 字符。 8 [file.readlines(sizeint])读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 9 [file.seek(offset, whence])移动文件读取指针到指定位置 10 file.tell()返回文件当前位置。 11 [file.truncate(size])从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 windows 系统下的换行代表2个字符大小。 12 file.write(str)将字符串写入文件,返回的是写入的字符长度。 13 file.writelines(sequence)向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。
OS
os 模块提供了非常丰富的方法用来处理文件和目录。常用的方法如下表所示:
序号 方法及描述 1 os.access(path, mode) 检验权限模式 2 os.chdir(path) 改变当前工作目录 3 os.chflags(path, flags) 设置路径的标记为数字标记。 4 os.chmod(path, mode) 更改权限 5 os.chown(path, uid, gid) 更改文件所有者 6 os.chroot(path) 改变当前进程的根目录 7 os.close(fd) 关闭文件描述符 fd 8 os.closerange(fd_low, fd_high) 关闭所有文件描述符,从 fd_low (包含) 到 fd_high (不包含), 错误会忽略 9 os.dup(fd) 复制文件描述符 fd 10 os.dup2(fd, fd2) 将一个文件描述符 fd 复制到另一个 fd2 11 os.fchdir(fd) 通过文件描述符改变当前工作目录 12 os.fchmod(fd, mode) 改变一个文件的访问权限,该文件由参数fd指定,参数mode是Unix下的文件访问权限。 13 os.fchown(fd, uid, gid) 修改一个文件的所有权,这个函数修改一个文件的用户ID和用户组ID,该文件由文件描述符fd指定。 14 os.fdatasync(fd) 强制将文件写入磁盘,该文件由文件描述符fd指定,但是不强制更新文件的状态信息。 15 [os.fdopen(fd, mode[, bufsize]]) 通过文件描述符 fd 创建一个文件对象,并返回这个文件对象 16 os.fpathconf(fd, name) 返回一个打开的文件的系统配置信息。name为检索的系统配置的值,它也许是一个定义系统值的字符串,这些名字在很多标准中指定(POSIX.1, Unix 95, Unix 98, 和其它)。 17 os.fstat(fd) 返回文件描述符fd的状态,像stat()。 18 os.fstatvfs(fd) 返回包含文件描述符fd的文件的文件系统的信息,Python 3.3 相等于 statvfs()。 19 os.fsync(fd) 强制将文件描述符为fd的文件写入硬盘。 20 os.ftruncate(fd, length) 裁剪文件描述符fd对应的文件, 所以它最大不能超过文件大小。 21 os.getcwd() 返回当前工作目录 22 os.getcwdb() 返回一个当前工作目录的Unicode对象 23 os.isatty(fd) 如果文件描述符fd是打开的,同时与tty(-like)设备相连,则返回true, 否则False。 24 os.lchflags(path, flags) 设置路径的标记为数字标记,类似 chflags(),但是没有软链接 25 os.lchmod(path, mode) 修改连接文件权限 26 os.lchown(path, uid, gid) 更改文件所有者,类似 chown,但是不追踪链接。 27 os.link(src, dst) 创建硬链接,名为参数 dst,指向参数 src 28 os.listdir(path) 返回path指定的文件夹包含的文件或文件夹的名字的列表。 29 os.lseek(fd, pos, how) 设置文件描述符 fd当前位置为pos, how方式修改: SEEK_SET 或者 0 设置从文件开始的计算的pos; SEEK_CUR或者 1 则从当前位置计算; os.SEEK_END或者2则从文件尾部开始. 在unix,Windows中有效 30 os.lstat(path) 像stat(),但是没有软链接 31 os.major(device) 从原始的设备号中提取设备major号码 (使用stat中的st_dev或者st_rdev field)。 32 os.makedev(major, minor) 以major和minor设备号组成一个原始设备号 33 [os.makedirs(path, mode]) 递归文件夹创建函数。像mkdir(), 但创建的所有intermediate-level文件夹需要包含子文件夹。 34 os.minor(device) 从原始的设备号中提取设备minor号码 (使用stat中的st_dev或者st_rdev field )。 35 [os.mkdir(path, mode]) 以数字mode的mode创建一个名为path的文件夹.默认的 mode 是 0777 (八进制)。 36 [os.mkfifo(path, mode]) 创建命名管道,mode 为数字,默认为 0666 (八进制) 37 [os.mknod(filename, mode=0600, device]) 创建一个名为filename文件系统节点(文件,设备特别文件或者命名pipe)。 38 [os.open(file, flags, mode]) 打开一个文件,并且设置需要的打开选项,mode参数是可选的 39 os.openpty() 打开一个新的伪终端对。返回 pty 和 tty的文件描述符。 40 os.pathconf(path, name) 返回相关文件的系统配置信息。 41 os.pipe() 创建一个管道. 返回一对文件描述符(r, w) 分别为读和写 42 [os.popen(command, mode[, bufsize]]) 从一个 command 打开一个管道 43 os.read(fd, n) 从文件描述符 fd 中读取最多 n 个字节,返回包含读取字节的字符串,文件描述符 fd对应文件已达到结尾, 返回一个空字符串。 44 os.readlink(path) 返回软链接所指向的文件 45 os.remove(path) 删除路径为path的文件。如果path 是一个文件夹,将抛出OSError; 查看下面的rmdir()删除一个 directory。 46 os.removedirs(path) 递归删除目录。 47 os.rename(src, dst) 重命名文件或目录,从 src 到 dst 48 os.renames(old, new) 递归地对目录进行更名,也可以对文件进行更名。 49 os.rmdir(path) 删除path指定的空目录,如果目录非空,则抛出一个OSError异常。 50 os.stat(path) 获取path指定的路径的信息,功能等同于C API中的stat()系统调用。 51 [os.stat_float_times(newvalue]) 决定stat_result是否以float对象显示时间戳 52 os.statvfs(path) 获取指定路径的文件系统统计信息 53 os.symlink(src, dst) 创建一个软链接 54 os.tcgetpgrp(fd) 返回与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组 55 os.tcsetpgrp(fd, pg) 设置与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组为pg。 56 os.tempnam([dir[, prefix]]) Python3 中已删除。返回唯一的路径名用于创建临时文件。 57 os.tmpfile() Python3 中已删除。返回一个打开的模式为(w+b)的文件对象 .这文件对象没有文件夹入口,没有文件描述符,将会自动删除。 58 os.tmpnam() Python3 中已删除。为创建一个临时文件返回一个唯一的路径 59 os.ttyname(fd) 返回一个字符串,它表示与文件描述符fd 关联的终端设备。如果fd 没有与终端设备关联,则引发一个异常。 60 os.unlink(path) 删除文件路径 61 os.utime(path, times) 返回指定的path文件的访问和修改的时间。 62 [os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]])](https://www.runoob.com/python3/python3-os-walk.html) 输出在文件夹中的文件名通过在树中游走,向上或者向下。 63 os.write(fd, str) 写入字符串到文件描述符 fd中. 返回实际写入的字符串长度 64 os.path 模块 获取文件的属性信息。 65 os.pardir() 获取当前目录的父目录,以字符串形式显示目录名。 错误与异常处理
语法错误 - 语法分析器检测到错误
异常 -运行期检测到的错误
异常处理
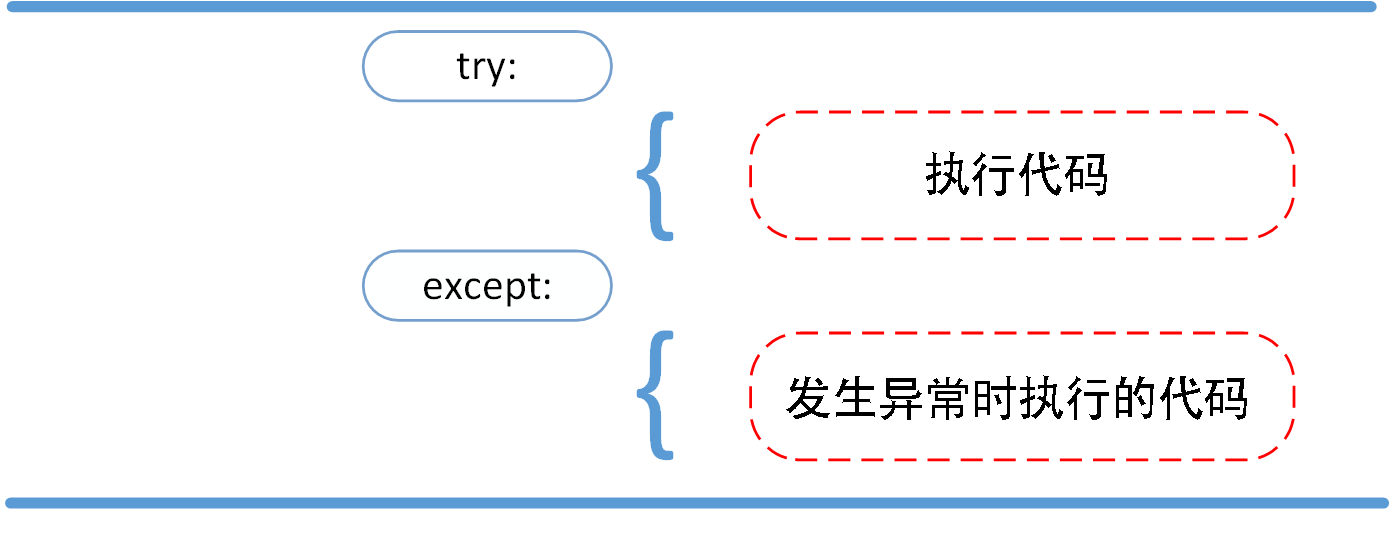
try/except
以下例子中,让用户输入一个合法的整数,但是允许用户中断这个程序(使用 Control-C 或者操作系统提供的方法)。用户中断的信息会引发一个 KeyboardInterrupt 异常。
1
2
3
4
5
6while True:
try:
x = int(input("请输入一个数字: "))
break
except ValueError:
print("您输入的不是数字,请再次尝试输入!")try 语句按照如下方式工作;
- 首先,执行 try 子句(在关键字 try 和关键字 except 之间的语句)。
- 如果没有异常发生,忽略 except 子句,try 子句执行后结束。
- 如果在执行 try 子句的过程中发生了异常,那么 try 子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的 except 子句将被执行。
- 如果一个异常没有与任何的 except 匹配,那么这个异常将会传递给上层的 try 中。
一个 try 语句可能包含多个except子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。
处理程序将只针对对应的 try 子句中的异常进行处理,而不是其他的 try 的处理程序中的异常。
一个except子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组,例如:
1
2except (RuntimeError, TypeError, NameError):
pass最后一个except子句可以忽略异常的名称,它将被当作通配符使用。你可以使用这种方法打印一个错误信息,然后再次把异常抛出。
1
2
3
4
5
6
7
8
9
10
11
12
13import sys
try:
f = open('myfile.txt')
s = f.readline()
i = int(s.strip())
except OSError as err:
print("OS error: {0}".format(err))
except ValueError:
print("Could not convert data to an integer.")
except:
print("Unexpected error:", sys.exc_info()[0])
raisetry/except…else
try/except 语句还有一个可选的 else 子句,如果使用这个子句,那么必须放在所有的 except 子句之后。
else 子句将在 try 子句没有发生任何异常的时候执行。

1
2
3
4
5
6
7
8for arg in sys.argv[1:]:
try:
f = open(arg, 'r')
except IOError:
print('cannot open', arg)
else:
print(arg, 'has', len(f.readlines()), 'lines')
f.close()使用 else 子句比把所有的语句都放在 try 子句里面要好,这样可以避免一些意想不到,而 except 又无法捕获的异常。
异常处理并不仅仅处理那些直接发生在 try 子句中的异常,而且还能处理子句中调用的函数(甚至间接调用的函数)里抛出的异常。例如:
1
2
3
4
5
6
7
8def this_fails():
x = 1/0
try:
this_fails()
except ZeroDivisionError as err:
print('Handling run-time error:', err)
Handling run-time error: int division or modulo by zerotry-finally
try-finally 语句无论是否发生异常都将执行最后的代码。

1
2
3
4
5
6
7
8
9
10
11
12try:
runoob()
except AssertionError as error:
print(error)
else:
try:
with open('file.log') as file:
read_data = file.read()
except FileNotFoundError as fnf_error:
print(fnf_error)
finally:
print('这句话,无论异常是否发生都会执行。')
抛出异常
Python 使用 raise 语句抛出一个指定的异常。
raise语法格式如下:
1
raise [Exception [, args [, traceback]]]
1
2
3
4
5
6
7
8
9x = 10
if x > 5:
raise Exception('x 不能大于 5。x 的值为: {}'.format(x))
执行以上代码会触发异常:
Traceback (most recent call last):
File "test.py", line 3, in <module>
raise Exception('x 不能大于 5。x 的值为: {}'.format(x))
Exception: x 不能大于 5。x 的值为: 10raise 唯一的一个参数指定了要被抛出的异常。它必须是一个异常的实例或者是异常的类(也就是 Exception 的子类)。
如果你只想知道这是否抛出了一个异常,并不想去处理它,那么一个简单的 raise 语句就可以再次把它抛出。
1
2
3
4
5
6
7
8
9
10
11try:
raise NameError('HiThere')
except NameError:
print('An exception flew by!')
raise
An exception flew by!
Traceback (most recent call last):
File "<stdin>", line 2, in ?
NameError: HiThere
理解:用户自定义异常
创建一个新的异常类来拥有自己的异常。异常类继承自 Exception 类,可以直接继承,或者间接继承,例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class MyError(Exception):
def __init__(self, value):
self.value = value
def __str__(self):
return repr(self.value)
try:
raise MyError(2*2)
except MyError as e:
print('My exception occurred, value:', e.value)
My exception occurred, value: 4
raise MyError('oops!')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
__main__.MyError: 'oops!'当创建一个模块有可能抛出多种不同的异常时,一种通常的做法是为这个包建立一个基础异常类,然后基于这个基础类为不同的错误情况创建不同的子类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30class Error(Exception):
"""Base class for exceptions in this module."""
pass
class InputError(Error):
"""Exception raised for errors in the input.
Attributes:
expression -- input expression in which the error occurred
message -- explanation of the error
"""
def __init__(self, expression, message):
self.expression = expression
self.message = message
class TransitionError(Error):
"""Raised when an operation attempts a state transition that's not
allowed.
Attributes:
previous -- state at beginning of transition
next -- attempted new state
message -- explanation of why the specific transition is not allowed
"""
def __init__(self, previous, next, message):
self.previous = previous
self.next = next
self.message = message定义清理行为
try 语句还有另外一个可选的子句,它定义了无论在任何情况下都会执行的清理行为。 例如:
1
2
3
4
5
6
7
8
9try:
raise KeyboardInterrupt
finally:
print('Goodbye, world!')
...
Goodbye, world!
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
KeyboardInterrupt以上例子不管 try 子句里面有没有发生异常,finally 子句都会执行。
如果一个异常在 try 子句里(或者在 except 和 else 子句里)被抛出,而又没有任何的 except 把它截住,那么这个异常会在 finally 子句执行后被抛出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22def divide(x, y):
try:
result = x / y
except ZeroDivisionError:
print("division by zero!")
else:
print("result is", result)
finally:
print("executing finally clause")
divide(2, 1)
result is 2.0
executing finally clause
divide(2, 0)
division by zero!
executing finally clause
divide("2", "1")
executing finally clause
Traceback (most recent call last):
File "<stdin>", line 1, in ?
File "<stdin>", line 3, in divide
TypeError: unsupported operand type(s) for /: 'str' and 'str'预定义的清理行为
一些对象定义了标准的清理行为,无论系统是否成功的使用了它,一旦不需要它了,那么这个标准的清理行为就会执行。
这面这个例子展示了尝试打开一个文件,然后把内容打印到屏幕上:
1
2for line in open("myfile.txt"):
print(line, end="")以上这段代码的问题是,当执行完毕后,文件会保持打开状态,并没有被关闭。
关键词 with 语句就可以保证诸如文件之类的对象在使用完之后一定会正确的执行他的清理方法:
1
2
3with open("myfile.txt") as f:
for line in f:
print(line, end="")以上这段代码执行完毕后,就算在处理过程中出问题了,文件 f 总是会关闭。
面向对象
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 方法:类中定义的函数。
- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 局部变量:定义在方法中的变量,只作用于当前实例的类。
- 实例变量:在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用 self 修饰的变量。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟”是一个(is-a)”关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
和其它编程语言相比,Python 在尽可能不增加新的语法和语义的情况下加入了类机制。
Python中的类提供了面向对象编程的所有基本功能:类的继承机制允许多个基类,派生类可以覆盖基类中的任何方法,方法中可以调用基类中的同名方法。
对象可以包含任意数量和类型的数据。
类定义
1
2
3
4
5
6class ClassName:
<statement-1>
.
.
.
<statement-N>类实例化后,可以使用其属性,实际上,创建一个类之后,可以通过类名访问其属性。
类对象
类对象支持两种操作:属性引用和实例化。
属性引用使用和 Python 中所有的属性引用一样的标准语法:obj.name。
类对象创建后,类命名空间中所有的命名都是有效属性名。所以如果类定义是这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14#!/usr/bin/python3
class MyClass:
"""一个简单的类实例"""
i = 12345
def f(self):
return 'hello world'
# 实例化类
x = MyClass()
# 访问类的属性和方法
print("MyClass 类的属性 i 为:", x.i)
print("MyClass 类的方法 f 输出为:", x.f())类有一个名为 init() 的特殊方法(构造方法),该方法在类实例化时会自动调用,像下面这样:
1
2def __init__(self):
self.data = []self是类的一个实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
1
2
3
4
5
6
7
8
9
10
11class Test:
def prt(self):
print(self)
print(self.__class__)
t = Test()
t.prt()
以上实例执行结果为:
<__main__.Test instance at 0x100771878>
__main__.Test从执行结果可以很明显的看出,self 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类。
self 不是 python 关键字,我们把他换成 runoob 也是可以正常执行的:
1
2
3
4
5
6class Test:
def prt(runoob):
print(runoob)
print(runoob.__class__)
t = Test()
t.prt()以上实例执行结果为:
1
2<__main__.Test instance at 0x100771878>
__main__.Test类方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self, 且为第一个参数,self 代表的是类的实例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
# 实例化类
p = people('runoob',10,30)
p.speak()
执行以上程序输出结果为:
runoob 说: 我 10 岁。继承
Python 同样支持类的继承,如果一种语言不支持继承,类就没有什么意义。派生类的定义如下所示:
1
2
3
4
5
6class DerivedClassName(BaseClassName):
<statement-1>
.
.
.
<statement-N>子类(派生类 DerivedClassName)会继承父类(基类 BaseClassName)的属性和方法。
BaseClassName(实例中的基类名)必须与派生类定义在一个作用域内。除了类,还可以用表达式,基类定义在另一个模块中时这一点非常有用:
1
class DerivedClassName(modname.BaseClassName):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35#!/usr/bin/python3
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
s = student('ken',10,60,3)
s.speak()
执行以上程序输出结果为:
ken 说: 我 10 岁了,我在读 3 年级多继承
Python同样有限的支持多继承形式。多继承的类定义形如下例:
1
2
3
4
5
6class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
#另一个类,多重继承之前的准备
class speaker():
topic = ''
name = ''
def __init__(self,n,t):
self.name = n
self.topic = t
def speak(self):
print("我叫 %s,我是一个演说家,我演讲的主题是 %s"%(self.name,self.topic))
#多重继承
class sample(speaker,student):
a =''
def __init__(self,n,a,w,g,t):
student.__init__(self,n,a,w,g)
speaker.__init__(self,n,t)
test = sample("Tim",25,80,4,"Python")
test.speak() #方法名同,默认调用的是在括号中参数位置排前父类的方法
执行以上程序输出结果为:
我叫 Tim,我是一个演说家,我演讲的主题是 Python方法重写
如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法,实例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16#!/usr/bin/python3
class Parent: # 定义父类
def myMethod(self):
print ('调用父类方法')
class Child(Parent): # 定义子类
def myMethod(self):
print ('调用子类方法')
c = Child() # 子类实例
c.myMethod() # 子类调用重写方法
super(Child,c).myMethod() #用子类对象调用父类已被覆盖的方法
执行以上程序输出结果为:
调用子类方法
调用父类方法类属性与方法
私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25#!/usr/bin/python3
class JustCounter:
__secretCount = 0 # 私有变量
publicCount = 0 # 公开变量
def count(self):
self.__secretCount += 1
self.publicCount += 1
print (self.__secretCount)
counter = JustCounter()
counter.count()
counter.count()
print (counter.publicCount)
print (counter.__secretCount) # 报错,实例不能访问私有变量
执行以上程序输出结果为:
1
2
2
Traceback (most recent call last):
File "test.py", line 16, in <module>
print (counter.__secretCount) # 报错,实例不能访问私有变量
AttributeError: 'JustCounter' object has no attribute '__secretCount'类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数,self 代表的是类的实例。
self 的名字并不是规定死的,也可以使用 this,但是最好还是按照约定使用 self。
私有方法
__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Site:
def __init__(self, name, url):
self.name = name # public
self.__url = url # private
def who(self):
print('name : ', self.name)
print('url : ', self.__url)
def __foo(self): # 私有方法
print('这是私有方法')
def foo(self): # 公共方法
print('这是公共方法')
self.__foo()
x = Site('菜鸟教程', 'www.runoob.com')
x.who() # 正常输出
x.foo() # 正常输出
x.__foo() # 报错专有方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14__init__ : 构造函数,在生成对象时调用
__del__ : 析构函数,释放对象时使用
__repr__ : 打印,转换
__setitem__ : 按照索引赋值
__getitem__: 按照索引获取值
__len__: 获得长度
__cmp__: 比较运算
__call__: 函数调用
__add__: 加运算
__sub__: 减运算
__mul__: 乘运算
__truediv__: 除运算
__mod__: 求余运算
__pow__: 乘方运算符重载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self,other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2,10)
v2 = Vector(5,-2)
print (v1 + v2)
以上代码执行结果如下所示:
Vector(7,8)
命名空间/作用域
命名空间(Namespace)是从名称到对象的映射,大部分的命名空间都是通过 Python 字典来实现的。
命名空间提供了在项目中避免名字冲突的一种方法。各个命名空间是独立的,没有任何关系的,所以一个命名空间中不能有重名,但不同的命名空间是可以重名而没有任何影响。
一般有三种命名空间:
- 内置名称(built-in names), Python 语言内置的名称,比如函数名 abs、char 和异常名称 BaseException、Exception 等等。
- 全局名称(global names),模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
- 局部名称(local names),函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是)
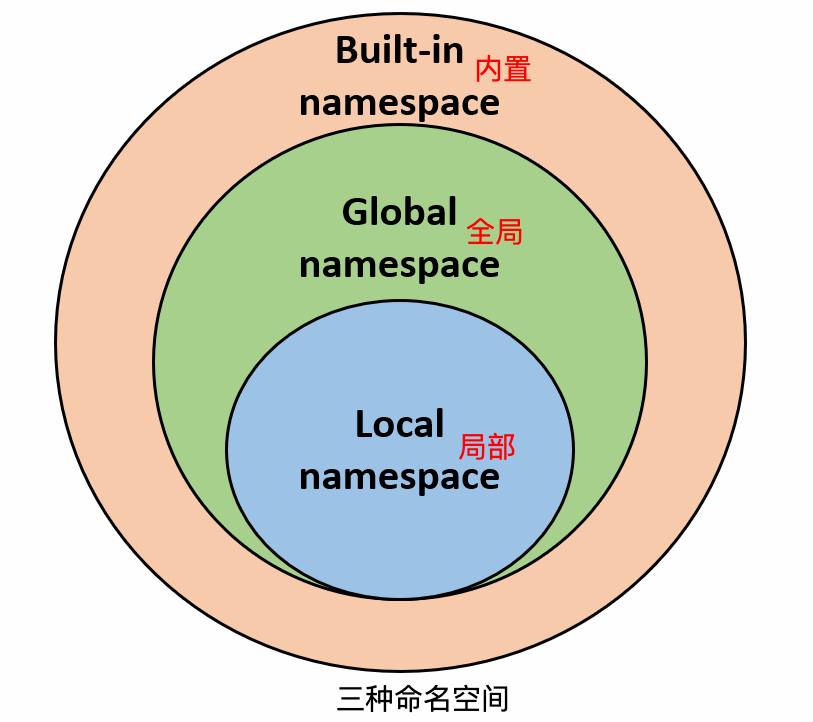
- 命名空间查找顺序:
假设我们要使用变量 runoob,则 Python 的查找顺序为:局部的命名空间去 -> 全局命名空间 -> 内置命名空间。
如果找不到变量 runoob,它将放弃查找并引发一个 NameError 异常:
1
NameError: name 'runoob' is not defined。
- 命名空间的生命周期:
命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。
因此,我们无法从外部命名空间访问内部命名空间的对象。
作用域
作用域就是一个 Python 程序可以直接访问命名空间的正文区域。
在一个 python 程序中,直接访问一个变量,会从内到外依次访问所有的作用域直到找到,否则会报未定义的错误。
Python 中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。Python 的作用域一共有4种,分别是:
有四种作用域:
- L(Local):最内层,包含局部变量,比如一个函数/方法内部。
- E(Enclosing):包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
- G(Global):当前脚本的最外层,比如当前模块的全局变量。
- B(Built-in): 包含了内建的变量/关键字等,最后被搜索。
规则顺序: L –> E –> G –> B。
在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内置中找。

全局和局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。
global 和nolocal 关键字
当内部作用域想修改外部作用域的变量时,就要用到 global 和 nonlocal 关键字了
1
2
3
4
5
6
7
8
9
10
11
12
13num = 1
def fun1():
global num # 需要使用 global 关键字声明
print(num)
num = 123
print(num)
fun1()
print(num)
以上实例输出结果:
1
123
123如果要修改嵌套作用域(enclosing 作用域,外层非全局作用域)中的变量则需要 nonlocal 关键字了
1
2
3
4
5
6
7
8
9
10
11
12
13def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()
以上实例输出结果:
100
100
标准库
二、高级
正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
匹配字符串
re.match() 函数
re.match 尝试从字符串的起始位置匹配一个模式,匹配成功re.match方法返回一个匹配的对象,否则返回None。
1
re.match(pattern, string, flags=0)
参数 描述 pattern 匹配的正则表达式 string 要匹配的字符串。 flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 re.search()
re.search 扫描整个字符串并返回第一个成功的匹配。匹配成功re.search方法返回一个匹配的对象,否则返回None。
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。
检索替换
re.sub()
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
1
re.sub(pattern, repl, string, count=0, flags=0)
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags : 编译时用的匹配模式,数字形式。
CGI编程
MySql(mysql-connector)
MySql(pymysql)
网络编程
Python 提供了两个级别访问的网络服务。:
- 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统Socket接口的全部方法。
- 高级别的网络服务模块 SocketServer, 它提供了服务器中心类,可以简化网络服务器的开发。
什么是socket?
Socket又称”套接字”,应用程序通常通过”套接字”向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯。
socket()函数
1
2
3我们用 socket() 函数来创建套接字,语法格式如下:
socket.socket([family[, type[, proto]]])- family: 套接字家族可以是 AF_UNIX 或者 AF_INET
- type: 套接字类型可以根据是面向连接的还是非连接分为
SOCK_STREAM或SOCK_DGRAM - protocol: 一般不填默认为0.
函数 描述 服务器端套接字 s.bind() 绑定地址(host,port)到套接字, 在AF_INET下,以元组(host,port)的形式表示地址。 s.listen() 开始TCP监听。backlog指定在拒绝连接之前,操作系统可以挂起的最大连接数量。该值至少为1,大部分应用程序设为5就可以了。 s.accept() 被动接受TCP客户端连接,(阻塞式)等待连接的到来 客户端套接字 s.connect() 主动初始化TCP服务器连接,。一般address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。 s.connect_ex() connect()函数的扩展版本,出错时返回出错码,而不是抛出异常 公共用途的套接字函数 s.recv() 接收TCP数据,数据以字符串形式返回,bufsize指定要接收的最大数据量。flag提供有关消息的其他信息,通常可以忽略。 s.send() 发送TCP数据,将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。 s.sendall() 完整发送TCP数据,完整发送TCP数据。将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。 s.recvfrom() 接收UDP数据,与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。 s.sendto() 发送UDP数据,将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。 s.close() 关闭套接字 s.getpeername() 返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。 s.getsockname() 返回套接字自己的地址。通常是一个元组(ipaddr,port) s.setsockopt(level,optname,value) 设置给定套接字选项的值。 s.getsockopt(level,optname[.buflen]) 返回套接字选项的值。 s.settimeout(timeout) 设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如connect()) s.gettimeout() 返回当前超时期的值,单位是秒,如果没有设置超时期,则返回None。 s.fileno() 返回套接字的文件描述符。 s.setblocking(flag) 如果 flag 为 False,则将套接字设为非阻塞模式,否则将套接字设为阻塞模式(默认值)。非阻塞模式下,如果调用 recv() 没有发现任何数据,或 send() 调用无法立即发送数据,那么将引起 socket.error 异常。 s.makefile() 创建一个与该套接字相关连的文件 实例
- 服务端
我们使用 socket 模块的 socket 函数来创建一个 socket 对象。socket 对象可以通过调用其他函数来设置一个 socket 服务。
现在我们可以通过调用 bind(hostname, port) 函数来指定服务的 *port(端口)*。
接着,我们调用 socket 对象的 accept 方法。该方法等待客户端的连接,并返回 connection 对象,表示已连接到客户端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31#!/usr/bin/python3
# 文件名:server.py
# 导入 socket、sys 模块
import socket
import sys
# 创建 socket 对象
serversocket = socket.socket(
socket.AF_INET, socket.SOCK_STREAM)
# 获取本地主机名
host = socket.gethostname()
port = 9999
# 绑定端口号
serversocket.bind((host, port))
# 设置最大连接数,超过后排队
serversocket.listen(5)
while True:
# 建立客户端连接
clientsocket,addr = serversocket.accept()
print("连接地址: %s" % str(addr))
msg='欢迎访问菜鸟教程!'+ "\r\n"
clientsocket.send(msg.encode('utf-8'))
clientsocket.close()客户端
接下来我们写一个简单的客户端实例连接到以上创建的服务。端口号为 9999。
socket.connect(hostname, port ) 方法打开一个 TCP 连接到主机为 hostname 端口为 port 的服务商。连接后我们就可以从服务端获取数据,记住,操作完成后需要关闭连接。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25#!/usr/bin/python3
# 文件名:client.py
# 导入 socket、sys 模块
import socket
import sys
# 创建 socket 对象
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 获取本地主机名
host = socket.gethostname()
# 设置端口号
port = 9999
# 连接服务,指定主机和端口
s.connect((host, port))
# 接收小于 1024 字节的数据
msg = s.recv(1024)
s.close()
print (msg.decode('utf-8'))现在我们打开两个终端,第一个终端执行 server.py 文件:
1
$ python3 server.py
第二个终端执行 client.py 文件:
1
2$ python3 client.py
欢迎访问菜鸟教程!这时我们再打开第一个终端,就会看到有以下信息输出:
1
连接地址: ('192.168.0.118', 33397)
python Internet模块
以下列出了 Python 网络编程的一些重要模块:
协议 功能用处 端口号 Python 模块 HTTP 网页访问 80 httplib, urllib, xmlrpclib NNTP 阅读和张贴新闻文章,俗称为”帖子” 119 nntplib FTP 文件传输 20 ftplib, urllib SMTP 发送邮件 25 smtplib POP3 接收邮件 110 poplib IMAP4 获取邮件 143 imaplib Telnet 命令行 23 telnetlib Gopher 信息查找 70 gopherlib, urllib
SMTP发送发送邮件
多线程
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度。
- 程序的运行速度可能加快。
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
每个线程都有他自己的一组CPU寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的CPU寄存器的状态。
指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程得到上下文中运行的,这些地址都用于标志拥有线程的进程地址空间中的内存。
- 线程可以被抢占(中断)。
- 在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) – 这就是线程的退让。
线程可以分为:
- 内核线程:由操作系统内核创建和撤销。
- 用户线程:不需要内核支持而在用户程序中实现的线程。
Python3 线程中常用的两个模块为:
- _thread
- threading(推荐使用)
thread 模块已被废弃。用户可以使用 threading 模块代替。所以,在 Python3 中不能再使用”thread” 模块。为了兼容性,Python3 将 thread 重命名为 “_thread”。
Python中使用线程有两种方式:函数或者用类来包装线程对象。
函数式:调用 _thread 模块中的start_new_thread()函数来产生新线程。语法如下:
1
_thread.start_new_thread ( function, args[, kwargs] )
参数说明:
- function - 线程函数。
- args - 传递给线程函数的参数,他必须是个tuple类型。
- kwargs - 可选参数。
实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35#!/usr/bin/python3
import _thread
import time
# 为线程定义一个函数
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
# 创建两个线程
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: 无法启动线程")
while 1:
pass
执行以上程序输出结果如下:
Thread-1: Wed Jan 5 17:38:08 2022
Thread-2: Wed Jan 5 17:38:10 2022
Thread-1: Wed Jan 5 17:38:10 2022
Thread-1: Wed Jan 5 17:38:12 2022
Thread-2: Wed Jan 5 17:38:14 2022
Thread-1: Wed Jan 5 17:38:14 2022
Thread-1: Wed Jan 5 17:38:16 2022
Thread-2: Wed Jan 5 17:38:18 2022
Thread-2: Wed Jan 5 17:38:22 2022
Thread-2: Wed Jan 5 17:38:26 2022
执行以上程后可以按下 ctrl-c 退出。线程模块
Python3 通过两个标准库 _thread 和 threading 提供对线程的支持。
_thread 提供了低级别的、原始的线程以及一个简单的锁,它相比于 threading 模块的功能还是比较有限的。
threading 模块除了包含 _thread 模块中的所有方法外,还提供的其他方法:
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
run(): 用以表示线程活动的方法。
start():
启动线程活动。
join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
isAlive(): 返回线程是否活动的。
getName(): 返回线程名。
setName(): 设置线程名。
使用threading 模块创建线程
直接从 threading.Thread 继承创建一个新的子类,并实例化后调用 start() 方法启动新线程,即它调用了线程的 run() 方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, delay):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.delay = delay
def run(self):
print ("开始线程:" + self.name)
print_time(self.name, self.delay, 5)
print ("退出线程:" + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("退出主线程")
以上程序执行结果如下;
开始线程:Thread-1
开始线程:Thread-2
Thread-1: Wed Jan 5 17:34:54 2022
Thread-2: Wed Jan 5 17:34:55 2022
Thread-1: Wed Jan 5 17:34:55 2022
Thread-1: Wed Jan 5 17:34:56 2022
Thread-2: Wed Jan 5 17:34:57 2022
Thread-1: Wed Jan 5 17:34:57 2022
Thread-1: Wed Jan 5 17:34:58 2022
退出线程:Thread-1
Thread-2: Wed Jan 5 17:34:59 2022
Thread-2: Wed Jan 5 17:35:01 2022
Thread-2: Wed Jan 5 17:35:03 2022
退出线程:Thread-2
退出主线程线程同步
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。如下:
多线程的优势在于可以同时运行多个任务(至少感觉起来是这样)。但是当线程需要共享数据时,可能存在数据不同步的问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, delay):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.delay = delay
def run(self):
print ("开启线程: " + self.name)
# 获取锁,用于线程同步
threadLock.acquire()
print_time(self.name, self.delay, 3)
# 释放锁,开启下一个线程
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
threads = []
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
# 添加线程到线程列表
threads.append(thread1)
threads.append(thread2)
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")
执行以上程序,输出结果为:
开启线程: Thread-1
开启线程: Thread-2
Thread-1: Wed Jan 5 17:36:50 2022
Thread-1: Wed Jan 5 17:36:51 2022
Thread-1: Wed Jan 5 17:36:52 2022
Thread-2: Wed Jan 5 17:36:54 2022
Thread-2: Wed Jan 5 17:36:56 2022
Thread-2: Wed Jan 5 17:36:58 2022
退出主线程W线程优先级队列(Queue)
XML解析
JSON
日期时间
内置函数
MongoDB
urllib
uWSGI 安装配置
pip